Track Setting and Evaluation
Track Setting
Track 1: Low-Resource Multimodal Emotion and Intent Recognition. Collecting a large number of samples with emotion and intent labels is very challenging, which poses a significant barrier to the development of multimodal emotion and intent joint recognition. To address this issue, researchers typically focus on methods such as data augmentation to train robust models with limited data. Additionally, a large amount of unlabeled data can be introduced to improve model performance based on semi-supervised or unsupervised learning methods. Therefore, we propose the Low-Resource Multimodal Emotion and Intent Recognition Challenge to encourage participants to improve model performance through data augmentation or the design of semi-supervised methods.
Track 2: Imbalanced Emotion and Intent Recognition. In real life, the probabilities of people expressing different emotions or intents are not equal. For example, in peaceful everyday life, people are more inclined to express neutral or positive emotions (such as happiness or joy), while the probability of expressing negative emotions (such as anger or disgust) is lower. Therefore, the issue of category imbalance becomes a common and challenging scenario in real life. We set up a track focusing on the Category Imbalance problem, encouraging participants to propose interesting algorithms and model structures to improve the recognition performance of systems in situations with imbalanced categories.
Evaluation Metrics
For different tracks, we have chosen to use different evaluation metrics:
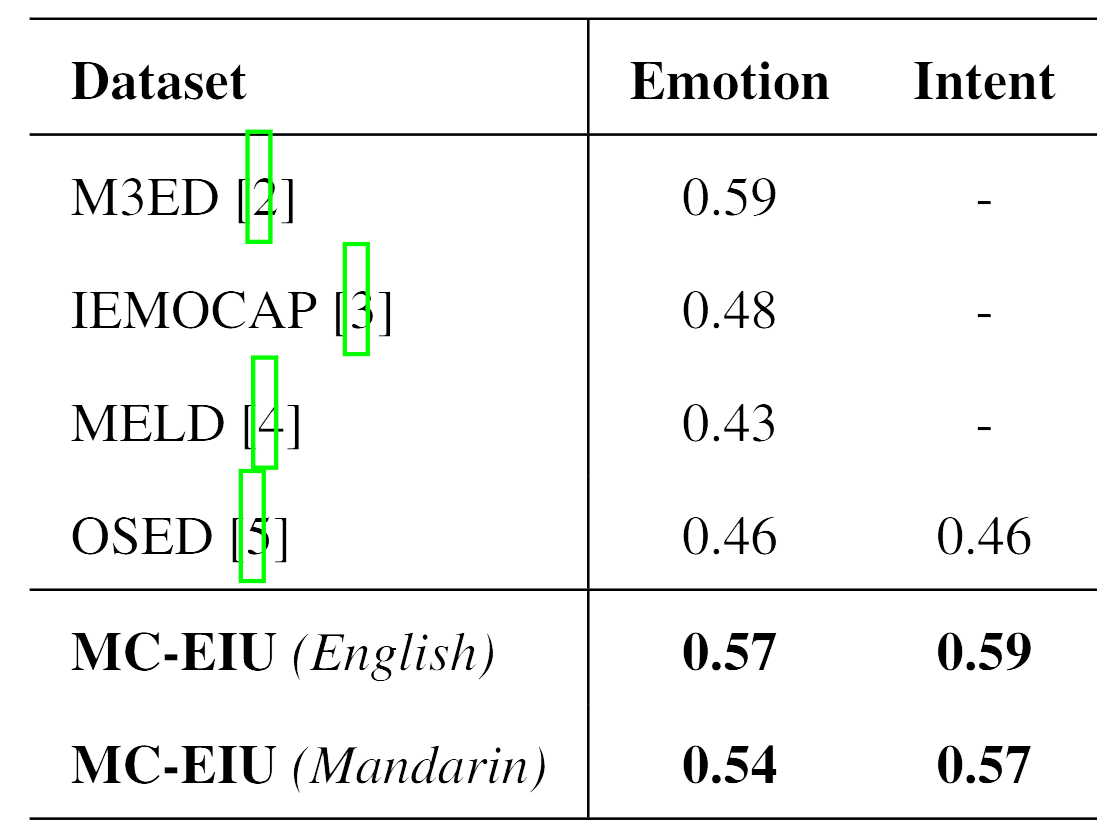
Track 1: We choose the weighted F-score, a metric widely used in emotion recognition, as the evaluation metric of emotion and intent recognition.
Track 2: Due to the category imbalance issue in Track 2, we choose to use the micro F-score instead of the weighted as the evaluation metric. The micro F-score treats all samples from all categories as equally important, thereby not being affected by category imbalance. This is particularly useful for evaluating category imbalance issues and can better reflect overall performance. Considering that our task involves joint recognition of emotions and intents, we additionally designed new evaluation metrics for all tracks, Joint Recognition Balance Metrics (JRBM), to balance the performance of both tasks:
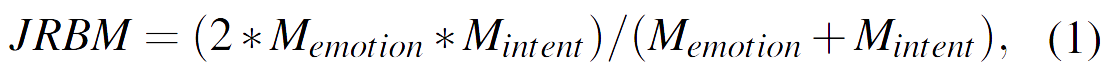
where M is the metric of corresponding tracks, weighted F-score or micro F-score. The JRBM is used to save the best model and as the final ranking. In addition, we will report the performances of emotion recognition and intent recognition separately in the final results.